Chemical Industry and Engineering Progress ›› 2022, Vol. 41 ›› Issue (9): 4691-4700.DOI: 10.16085/j.issn.1000-6613.2021-2466
• Chemical processes and equipment • Previous Articles Next Articles
Local modeling and optimization of K-means-PSO-SVR for methanol to aromatics
LIU Penglong1( ), XU Xiongfei1, ZHANG Wei1(), XU Xin1, ZHANG Kan2, WANG Junwen1
), XU Xiongfei1, ZHANG Wei1(), XU Xin1, ZHANG Kan2, WANG Junwen1
- 1.College of Chemistry and Chemical Engineering, Taiyuan University of Technology, Taiyuan 30024, Shanxi, China
2.Institute of Coal Chemistry, Chinese Academy of Sciences, Taiyuan 030001, Shanxi, China
-
Received:2021-12-01Revised:2022-03-03Online:2022-09-27Published:2022-09-25 -
Contact:ZHANG Wei
甲醇制芳烃K-means-PSO-SVR局部建模及优化
刘鹏龙1(), 许雄飞1, 张玮1(), 许鑫1, 张侃2, 王俊文1
- 1.太原理工大学化学化工学院,山西 太原 030024
2.中国科学院山西煤炭化学研究所,山西 太原 030001
-
通讯作者:张玮 -
作者简介:刘鹏龙(1997—),男,硕士研究生,研究方向为化工过程建模与优化。E-mail:642213917@qq.com。 -
基金资助:山西省重点研发计划(201903D121027);中科院关键技术人才项目(YB2021001);化学工程联合国家重点实验室开放课题(SKL-ChE-21A01);国家自然科学基金(22178241)
CLC Number:
Cite this article
LIU Penglong, XU Xiongfei, ZHANG Wei, XU Xin, ZHANG Kan, WANG Junwen. Local modeling and optimization of K-means-PSO-SVR for methanol to aromatics[J]. Chemical Industry and Engineering Progress, 2022, 41(9): 4691-4700.
刘鹏龙, 许雄飞, 张玮, 许鑫, 张侃, 王俊文. 甲醇制芳烃K-means-PSO-SVR局部建模及优化[J]. 化工进展, 2022, 41(9): 4691-4700.
share this article
Add to citation manager EndNote|Ris|BibTeX
URL: https://hgjz.cip.com.cn/EN/10.16085/j.issn.1000-6613.2021-2466
| 工艺条件 | 最低值 | 最高值 |
|---|---|---|
| 一段反应温度/℃ | 390 | 510 |
| 二段反应温度/℃ | 450 | 510 |
| 甲醇体积空速/h-1 | 0.1 | 0.5 |
| 反应压力/MPa | 0 | 0.8 |
| 工艺条件 | 最低值 | 最高值 |
|---|---|---|
| 一段反应温度/℃ | 390 | 510 |
| 二段反应温度/℃ | 450 | 510 |
| 甲醇体积空速/h-1 | 0.1 | 0.5 |
| 反应压力/MPa | 0 | 0.8 |
| 水平 | 一段反应 温度/℃ | 二段反应 温度/℃ | 甲醇体积 空速/h-1 | 反应 压力/MPa |
|---|---|---|---|---|
| 1 | 390 | 450 | 0.1 | 0 |
| 2 | 420 | 465 | 0.2 | 0.2 |
| 3 | 450 | 480 | 0.3 | 0.4 |
| 4 | 480 | 495 | 0.4 | 0.6 |
| 5 | 510 | 510 | 0.5 | 0.8 |
| 水平 | 一段反应 温度/℃ | 二段反应 温度/℃ | 甲醇体积 空速/h-1 | 反应 压力/MPa |
|---|---|---|---|---|
| 1 | 390 | 450 | 0.1 | 0 |
| 2 | 420 | 465 | 0.2 | 0.2 |
| 3 | 450 | 480 | 0.3 | 0.4 |
| 4 | 480 | 495 | 0.4 | 0.6 |
| 5 | 510 | 510 | 0.5 | 0.8 |

| 编号 | 一段反应 温度/℃ | 二段反应 温度/℃ | 甲醇体积 空速/h-1 | 反应 压力/MPa | BTX 总收率/% |
|---|---|---|---|---|---|
| 1 | 389.2 | 450.0 | 0.5 | 0 | 27.90 |
| 2 | 389.8 | 509.0 | 0.5 | 0 | 27.06 |
| 3 | 390.2 | 450.0 | 0.1 | 0 | 30.25 |
| 4 | 389.0 | 510.0 | 0.1 | 0 | 35.26 |
| 5 | 450.4 | 480.0 | 0.3 | 0 | 28.10 |
| 6 | 509.3 | 450.0 | 0.5 | 0 | 23.77 |
| 7 | 510.3 | 510.0 | 0.5 | 0 | 26.19 |
| 8 | 510.0 | 450.0 | 0.1 | 0 | 33.92 |
| … | … | … | … | … | … |
| 64 | 472.3 | 494.2 | 0.2 | 0.23 | 35.86 |
| 65 | 398.8 | 477.3 | 0.3 | 0.45 | 27.19 |
| 66 | 461.9 | 476.0 | 0.5 | 0.44 | 34.57 |
| 67 | 460.3 | 450.0 | 0.3 | 0.40 | 37.71 |
| 68 | 464.8 | 508.4 | 0.3 | 0.42 | 40.26 |
| 69 | 442.2 | 460.0 | 0.4 | 0.66 | 42.62 |
| 编号 | 一段反应 温度/℃ | 二段反应 温度/℃ | 甲醇体积 空速/h-1 | 反应 压力/MPa | BTX 总收率/% |
|---|---|---|---|---|---|
| 1 | 389.2 | 450.0 | 0.5 | 0 | 27.90 |
| 2 | 389.8 | 509.0 | 0.5 | 0 | 27.06 |
| 3 | 390.2 | 450.0 | 0.1 | 0 | 30.25 |
| 4 | 389.0 | 510.0 | 0.1 | 0 | 35.26 |
| 5 | 450.4 | 480.0 | 0.3 | 0 | 28.10 |
| 6 | 509.3 | 450.0 | 0.5 | 0 | 23.77 |
| 7 | 510.3 | 510.0 | 0.5 | 0 | 26.19 |
| 8 | 510.0 | 450.0 | 0.1 | 0 | 33.92 |
| … | … | … | … | … | … |
| 64 | 472.3 | 494.2 | 0.2 | 0.23 | 35.86 |
| 65 | 398.8 | 477.3 | 0.3 | 0.45 | 27.19 |
| 66 | 461.9 | 476.0 | 0.5 | 0.44 | 34.57 |
| 67 | 460.3 | 450.0 | 0.3 | 0.40 | 37.71 |
| 68 | 464.8 | 508.4 | 0.3 | 0.42 | 40.26 |
| 69 | 442.2 | 460.0 | 0.4 | 0.66 | 42.62 |
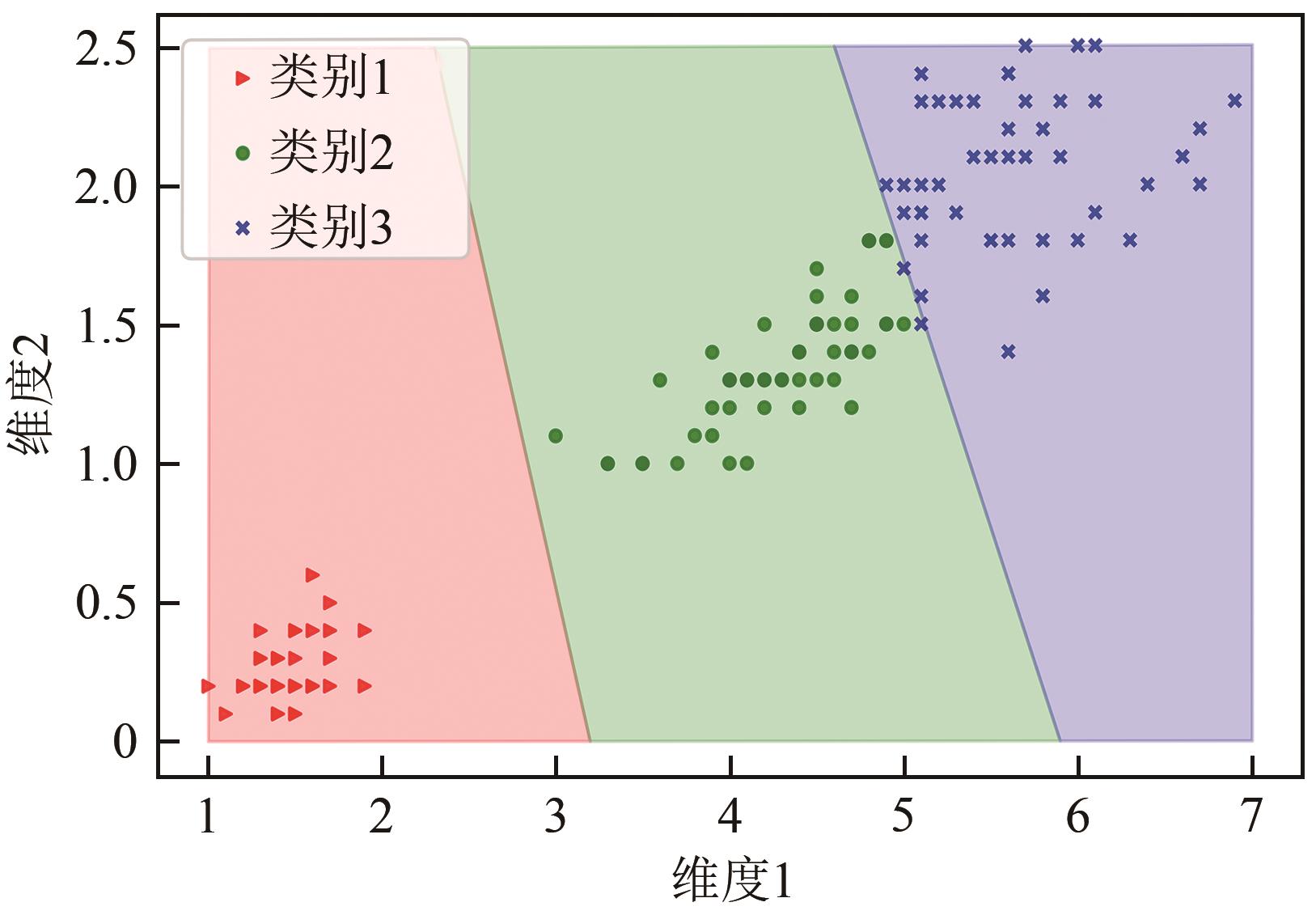
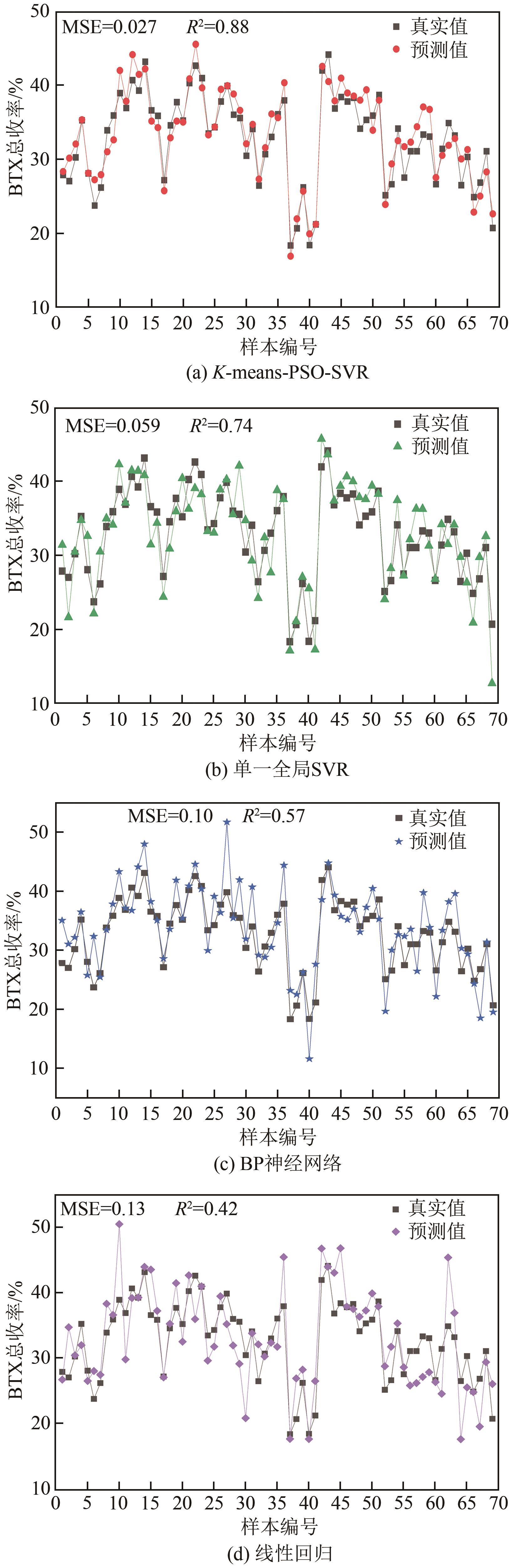
| 噪声水平/% | 建模算法 | MSE | R2 |
|---|---|---|---|
| 0 | K-means-PSO-SVR | 0.027 | 0.88 |
| 单一全局SVR | 0.059 | 0.74 | |
| BP神经网络 | 0.100 | 0.57 | |
| 线性回归 | 0.130 | 0.42 | |
| 10 | K-means-PSO-SVR | 0.042 | 0.81 |
| 单一全局SVR | 0.081 | 0.67 | |
| BP神经网络 | 0.112 | 0.51 | |
| 线性回归 | 0.149 | 0.36 | |
| 20 | K-means-PSO-SVR | 0.061 | 0.72 |
| 单一全局SVR | 0.103 | 0.57 | |
| BP神经网络 | 0.132 | 0.40 | |
| 线性回归 | 0.174 | 0.28 |
| 噪声水平/% | 建模算法 | MSE | R2 |
|---|---|---|---|
| 0 | K-means-PSO-SVR | 0.027 | 0.88 |
| 单一全局SVR | 0.059 | 0.74 | |
| BP神经网络 | 0.100 | 0.57 | |
| 线性回归 | 0.130 | 0.42 | |
| 10 | K-means-PSO-SVR | 0.042 | 0.81 |
| 单一全局SVR | 0.081 | 0.67 | |
| BP神经网络 | 0.112 | 0.51 | |
| 线性回归 | 0.149 | 0.36 | |
| 20 | K-means-PSO-SVR | 0.061 | 0.72 |
| 单一全局SVR | 0.103 | 0.57 | |
| BP神经网络 | 0.132 | 0.40 | |
| 线性回归 | 0.174 | 0.28 |
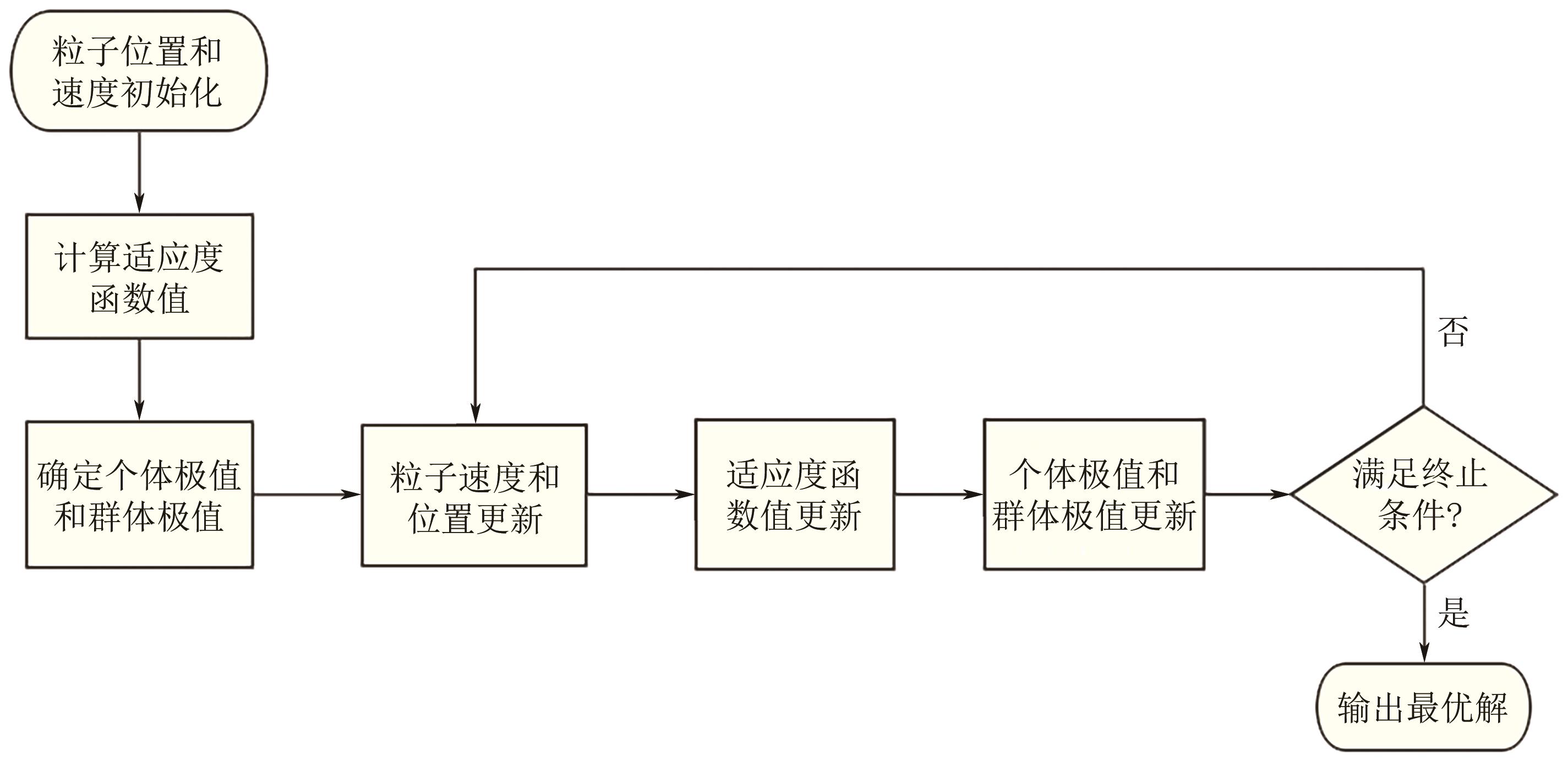
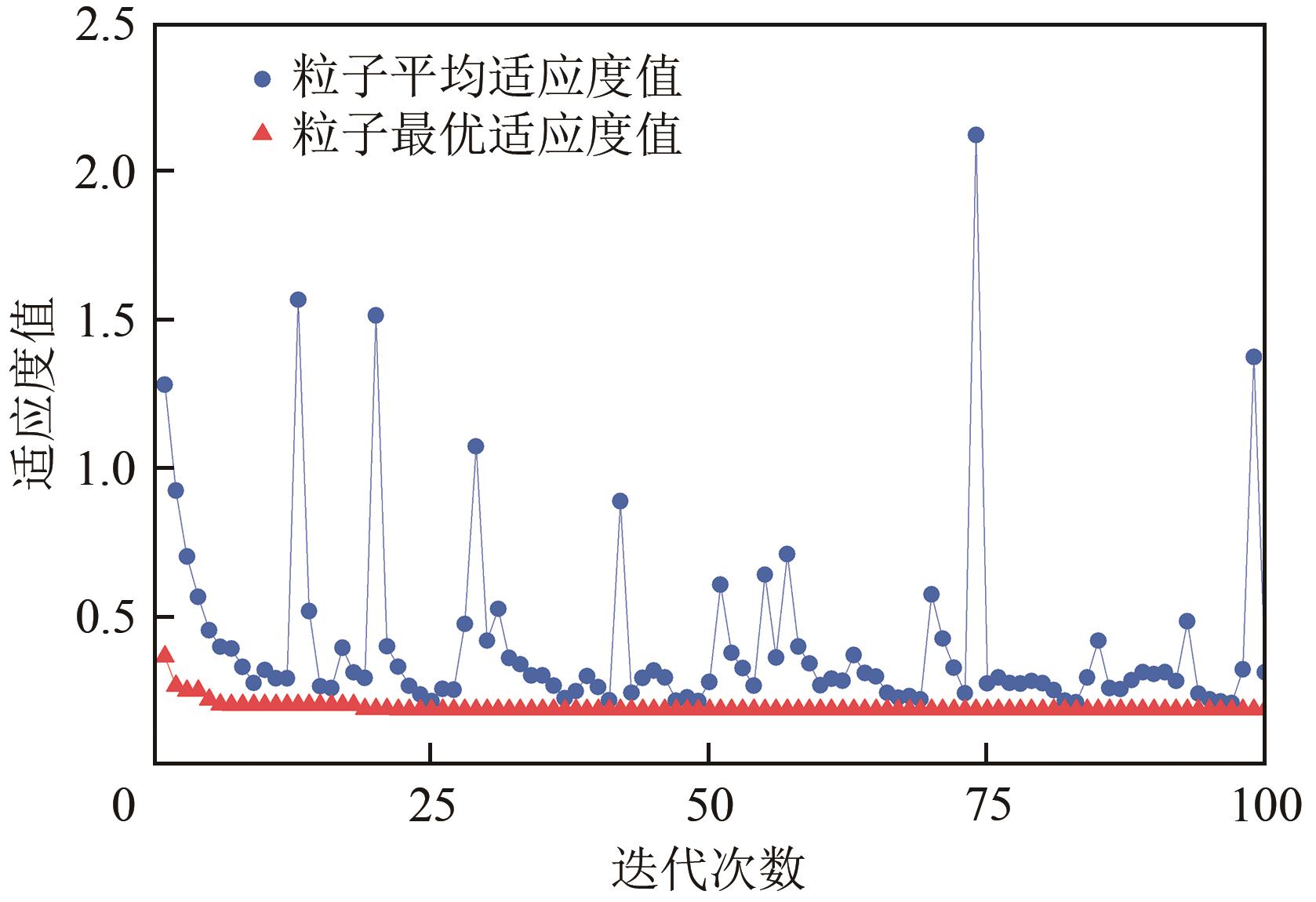
| 编号 | 一段反应 温度/℃ | 二段反应 温度/℃ | 甲醇体积 空速/h-1 | 反应 压力/MPa | BTX 总收率/% |
|---|---|---|---|---|---|
| 1 | 446.0 | 467.3 | 0.4 | 0.64 | 44.23 |
| 2 | 445.2 | 467.7 | 0.4 | 0.63 | 43.78 |
| 3 | 446.5 | 466.8 | 0.4 | 0.62 | 43.86 |
| 4 | 445.7 | 467.1 | 0.4 | 0.64 | 44.15 |
| 5 | 447.1 | 466.2 | 0.4 | 0.63 | 44.07 |
| 编号 | 一段反应 温度/℃ | 二段反应 温度/℃ | 甲醇体积 空速/h-1 | 反应 压力/MPa | BTX 总收率/% |
|---|---|---|---|---|---|
| 1 | 446.0 | 467.3 | 0.4 | 0.64 | 44.23 |
| 2 | 445.2 | 467.7 | 0.4 | 0.63 | 43.78 |
| 3 | 446.5 | 466.8 | 0.4 | 0.62 | 43.86 |
| 4 | 445.7 | 467.1 | 0.4 | 0.64 | 44.15 |
| 5 | 447.1 | 466.2 | 0.4 | 0.63 | 44.07 |
| 1 | 华经情报网. 中国对二甲苯行业产量、需求量及进口分析, 国内市场缺口依旧较大[EB/OL]. [2020-12-14]. . |
| huaon.com. The analysis of output, demand and import of China’s paraxylene industry, the gap in the domestic market is still large[EB/OL]. [2020-12-14]. . | |
| 2 | 黄格省, 包力庆, 丁文娟, 等. 我国煤制芳烃技术发展现状及产业前景分析[J]. 煤炭加工与综合利用, 2018(2): 6-10. |
| HUANG Gesheng, BAO Liqing, DING Wenjuan, et al. An analysis on status quo and prospect of Chinese coal to aromatics technologies[J]. Coal Processing & Comprehensive Utilization, 2018(2): 6-10. | |
| 3 | 代成义, 陈中顺, 杜康, 等. 甲醇制芳烃催化剂及相关工艺研究进展[J]. 化工进展, 2020, 39(12): 5029-5041. |
| DAI Chengyi, CHEN Zhongshun, DU Kang, et al. Research progress of catalysts and related technologies for methanol to aromatics[J]. Chemical Industry and Engineering Progress, 2020, 39(12): 5029-5041. | |
| 4 | 朱伟平, 李飞, 薛云鹏, 等. 甲醇制芳烃技术研究进展[J]. 现代化工, 2014, 34(7): 36-40, 42. |
| ZHU Weiping, LI Fei, XUE Yunpeng, et al. Advances in methanol to aromatics technology[J]. Modern Chemical Industry, 2014, 34(7): 36-40, 42. | |
| 5 | 张梦轩, 刘洪辰, 王敏, 等. 化工过程的智能混合建模方法及应用[J]. 化工进展, 2021, 40(4): 1765-1776. |
| ZHANG Mengxuan, LIU Hongchen, WANG Min, et al. Intelligence hybrid modelling method and applications in chemical process[J]. Chemical Industry and Engineering Progress, 2021, 40(4): 1765-1776. | |
| 6 | 徐亚荣, 蒋斌波, 冯丽梅, 等. 甲醇制芳烃(MTA)反应动力学的研究[J]. 聚酯工业, 2019, 32(6): 7-12. |
| XU Yarong, JIANG Binbo, FENG Limei, et al. Study on reaction dynamic of methanol to aromatic[J]. Polyester Industry, 2019, 32(6): 7-12. | |
| 7 | 施丽丽, 方栩, 刘殿华, 等. Zn改性ZSM-5催化甲醇制芳烃反应动力学[J]. 天然气化工(C1化学与化工), 2017, 42(2): 40-44, 49. |
| SHI Lili, FANG Xu, LIU Dianhua, et al. Kinetic model for reaction of methanol to aromatics on Zn modified ZSM-5 catalyst[J]. Natural Gas Chemical Industry, 2017, 42(2): 40-44, 49. | |
| 8 | KADLEC P, GABRYS B, STRANDT S. Data-driven soft sensors in the process industry[J]. Computers & Chemical Engineering, 2009, 33(4): 795-814. |
| 9 | 许雄飞, 刘鹏龙, 张玮, 等. 两段法固定床甲醇制芳烃产物预测多元非线性回归模型[J]. 化工学报, 2022, 73(2): 838-846. |
| XU Xiongfei, LIU Penglong, ZHANG Wei, et al. Multivariate nonlinear regression model of methanol to aromatics by two-state fixed bed for product prediction[J]. CIESC Journal, 2022, 73(2): 838-846. | |
| 10 | 熊伟丽, 姚乐, 徐保国. 混沌最小二乘支持向量机及其在发酵过程建模中的应用[J]. 化工学报, 2013, 64(12): 4585-4591. |
| XIONG Weili, YAO Le, XU Baoguo. Chaos least squares support vector machine and its application on fermentation process modeling[J]. CIESC Journal, 2013, 64(12): 4585-4591. | |
| 11 | SERRANO D, CASTELLÓ D. Tar prediction in bubbling fluidized bed gasification through artificial neural networks[J]. Chemical Engineering Journal, 2020, 402: 126229. |
| 12 | 李柠, 李少远, 席裕庚. 基于满意聚类的多模型建模方法[J]. 控制理论与应用, 2003, 20(5): 783-787. |
| LI Ning, LI Shaoyuan, XI Yugeng. Multi-model modeling method based on satisfactory clustering[J]. Control Theory & Applications, 2003, 20(5): 783-787. | |
| 13 | 王海宁, 夏陆岳, 周猛飞, 等. 过程工业软测量中的多模型融合建模方法[J]. 化工进展, 2014, 33(12): 3157-3163. |
| WANG Haining, XIA Luyue, ZHOU Mengfei, et al. Multi-model fusion modeling method for process industries soft sensor[J]. Chemical Industry and Engineering Progress, 2014, 33(12): 3157-3163. | |
| 26 | DU Shuxin, WU Tiejun. Support vector machines for regression[J]. Acta Simulata Systematica Sinica, 2003, 15(11): 1580-1585, 1633. |
| 27 | 邵信光, 杨慧中, 石晨曦. ε不敏感支持向量回归在化工数据建模中的应用[J]. 东南大学学报(自然科学版), 2004, 34(S1): 215-218. |
| SHAO Xinguang, YANG Huizhong, SHI Chenxi. Chemical process data modeling based on ε-insensitive support vector regression[J]. Journal of Southeast University (Natural Science Edition), 2004, 34(S1): 215-218. | |
| 28 | VAPNIK V N, GOLOWICH S, SMOLA A. Support vector machine for function approximation, regression estimation, and signal processing[C]// MOZER M, PETSCHE T. Advances in Neural Information Processing Systems 9, NTPS 1996. Cambridge, USA: MIT Press, 1997: 281-287. |
| 29 | DRUCKER H, BURGES C J C, KAUFMAN L, et al. Support vector regression machines [C]// MOZER M, PETSCHE T. Advances in Neural Information Processing Systems 9, NTPS 1996. Cambridge, USA: MIT Press, 1997: 155-161. |
| 30 | 张学工. 关于统计学习理论与支持向量机[J]. 自动化学报, 2000, 26(1): 32-42. |
| ZHANG Xuegong. Introduction to statistical learning theory and support vector machines[J]. Acta Automatica Sinica, 2000, 26(1): 32-42. | |
| 31 | 杨维, 李歧强. 粒子群优化算法综述[J]. 中国工程科学, 2004, 6(5): 87-94. |
| YANG Wei, LI Qiqiang. Survey on particle swarm optimization algorithm[J]. Engineering Science, 2004, 6(5): 87-94. | |
| 32 | 李爱国, 覃征, 鲍复民, 等. 粒子群优化算法[J]. 计算机工程与应用, 2002, 38(21): 1-3, 17. |
| LI Aiguo, QIN Zheng, BAO Fumin, et al. Particle swarm optimization algorithms[J]. Computer Engineering and Applications, 2002, 38(21): 1-3, 17. | |
| 14 | 仲蔚, 俞金寿. 基于模糊c均值聚类的多模型软测量建模[J]. 华东理工大学学报, 2000, 26(1): 83-87. |
| ZHONG Wei, YU Jinshou. Study on soft sensing modeling via FCM based multiple models[J]. Journal of East China University of Science and Technology, 2000, 26(1): 83-87. | |
| 15 | 李修亮, 苏宏业, 褚健. 基于在线聚类的多模型软测量建模方法[J]. 化工学报, 2007, 58(11): 2834-2839. |
| LI Xiuliang, SU Hongye, CHU Jian. Multiple models soft-sensing technique based on online clustering arithmetic[J]. CIESC Journal, 2007, 58(11): 2834-2839. | |
| 16 | 李丽娟, 宋坤, 赵英凯. 基于仿射传播聚类的ARA发酵过程建模[J]. 化工学报, 2011, 62(8): 2116-2121. |
| LI Lijuan, SONG Kun, ZHAO Yingkai. Modeling of ARA fermentation based on affinity propagation clustering[J]. CIESC Journal, 2011, 62(8): 2116-2121. | |
| 17 | 李文怀, 李凯旋, 张庆庚, 等. 一种固定床绝热反应器两步法甲醇转化制取烃类混合物的方法: CN106220462B[P]. 2019-01-25. |
| LI Wenhuai, LI Kaixuan, ZHANG Qinggeng, et al. The invention relates to a two-step methanol conversion method for producing hydrocarbon mixtures in a fixed bed adiabatic reactor: CN106220462B[P]. 2019-01-25. | |
| 18 | 张宝珠. 甲醇转化制芳烃(MTA)反应的研究[D]. 大连: 大连理工大学, 2013. |
| ZHANG Baozhu. Study on methanol to aromatics (MTA) reaction[D]. Dalian: Dalian University of Technology, 2013. | |
| 19 | 解峰, 黎汉生, 赵学良, 等. 甲醇在活性Al2O3催化剂表面的吸附与脱水反应[J]. 催化学报, 2004, 25(5): 403-408. |
| XIE Feng, LI Hansheng, ZHAO Xueliang, et al. Adsorption and dehydration of methanol on Al2O3 catalyst[J]. Chinese Journal of Catalysis, 2004, 25(5): 403-408. | |
| 20 | SEDIGHI M, BAHRAMI H, TOWFIGHI J. Kinetic modeling formulation of the methanol to olefin process: parameter estimation[J]. Journal of Industrial and Engineering Chemistry, 2014, 20(5): 3108-3114. |
| 21 | 刘艳, 常琴琴, 杨萌, 等. 甲醇制芳烃工艺研究进展[J]. 化学工程, 2015, 43(9): 74-78. |
| LIU Yan, CHANG Qinqin, YANG Meng, et al. Research progress of methanol to aromatics[J]. Chemical Engineering (China), 2015, 43(9): 74-78. | |
| 22 | OLSBYE U, BJØRGEN M, SVELLE S, et al. Mechanistic insight into the methanol-to-hydrocarbons reaction[J]. Catalysis Today, 2005, 106(1/2/3/4): 108-111. |
| 23 | ILIAS S, BHAN A. Tuning the selectivity of methanol-to-hydrocarbons conversion on H-ZSM-5 by co-processing olefin or aromatic compounds[J]. Journal of Catalysis, 2012, 290: 186-192. |
| 24 | 李航. 统计学习方法[M]. 2版. 北京: 清华大学出版社, 2019: 263-268. |
| LI Hang. Statistical learning method[M]. 2nd ed. Beijing: Tsinghua University Press, 2019: 263-268. | |
| 25 | 朱礼涛, 欧阳博, 张希宝, 等. 机器学习在多相反应器中的应用进展[J]. 化工进展, 2021, 40(4): 1699-1714. |
| ZHU Litao, OUYANG Bo, ZHANG Xibao, et al. Progress on application of machine learning to multiphase reactors[J]. Chemical Industry and Engineering Progress, 2021, 40(4): 1699-1714. | |
| 26 | 杜树新, 吴铁军. 用于回归估计的支持向量机方法[J]. 系统仿真学报, 2003, 15(11): 1580-1585, 1633. |
| [1] | WANG Zhengkun, LI Sifang. Green synthesis of gemini surfactant decyne diol [J]. Chemical Industry and Engineering Progress, 2023, 42(S1): 400-410. |
| [2] | LI Mengyuan, GUO Fan, LI Qunsheng. Simulation and optimization of the third and fourth distillation columns in the recovery section of polyvinyl alcohol production [J]. Chemical Industry and Engineering Progress, 2023, 42(S1): 113-123. |
| [3] | ZHANG Ruijie, LIU Zhilin, WANG Junwen, ZHANG Wei, HAN Deqiu, LI Ting, ZOU Xiong. On-line dynamic simulation and optimization of water-cooled cascade refrigeration system [J]. Chemical Industry and Engineering Progress, 2023, 42(S1): 124-132. |
| [4] | XU Chenyang, DU Jian, ZHANG Lei. Chemical reaction evaluation based on graph network [J]. Chemical Industry and Engineering Progress, 2023, 42(S1): 205-212. |
| [5] | WANG Fu'an. Consumption and emission reduction of the reactor of 300kt/a propylene oxide process [J]. Chemical Industry and Engineering Progress, 2023, 42(S1): 213-218. |
| [6] | LI Chunli, HAN Xiaoguang, LIU Jiapeng, WANG Yatao, WANG Chenxi, WANG Honghai, PENG Sheng. Research progress of liquid distributors in packed columns [J]. Chemical Industry and Engineering Progress, 2023, 42(9): 4479-4495. |
| [7] | ZHANG Fan, TAO Shaohui, CHEN Yushi, XIANG Shuguang. Initializing distillation column simulation based on the improved constant heat transport model [J]. Chemical Industry and Engineering Progress, 2023, 42(9): 4550-4558. |
| [8] | ZHANG Zhen, LI Dan, CHEN Chen, WU Jinglan, YING Hanjie, QIAO Hao. Separation and purification of salivary acids with adsorption resin [J]. Chemical Industry and Engineering Progress, 2023, 42(8): 4153-4158. |
| [9] | WU Zhenghao, ZHOU Tianhang, LAN Xingying, XU Chunming. AI-driven innovative design of chemicals in practice and perspective [J]. Chemical Industry and Engineering Progress, 2023, 42(8): 3910-3916. |
| [10] | ZHANG Zhichen, ZHU Yunfeng, CHENG Weishu, MA Shoutao, JIANG Jie, SUN Bing, ZHOU Zichen, XU Wei. Research advances on runaway decomposition of high pressure polyethylene: Reaction mechanism, initiation system and model [J]. Chemical Industry and Engineering Progress, 2023, 42(8): 3979-3989. |
| [11] | LI Haidong, YANG Yuankun, GUO Shushu, WANG Benjin, YUE Tingting, FU Kaibin, WANG Zhe, HE Shouqin, YAO Jun, CHEN Shu. Effect of carbonization and calcination temperature on As(Ⅲ) removal performance of plant-based Fe-C microelectrolytic materials [J]. Chemical Industry and Engineering Progress, 2023, 42(7): 3652-3663. |
| [12] | LIN Hai, WANG Yufei. Distributed wind farm layout optimization considering noise constraint [J]. Chemical Industry and Engineering Progress, 2023, 42(7): 3394-3403. |
| [13] | WANG Junjie, PAN Yanqiu, NIU Yabin, YU Lu. Molecular level catalytic reforming model construction and application [J]. Chemical Industry and Engineering Progress, 2023, 42(7): 3404-3412. |
| [14] | ZHAO Yi, YANG Zhen, ZHANG Xinwei, WANG Gang, YANG Xuan. Molecular simulation of self-healing behavior of asphalt under different crack damage and healing temperature [J]. Chemical Industry and Engineering Progress, 2023, 42(6): 3147-3156. |
| [15] | QIN Kai, YANG Shilin, LI Jun, CHU Zhenyu, BO Cuimei. A Kalman filter algorithm-based high precision detection method for glucoamylase biosensors [J]. Chemical Industry and Engineering Progress, 2023, 42(6): 3177-3186. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||