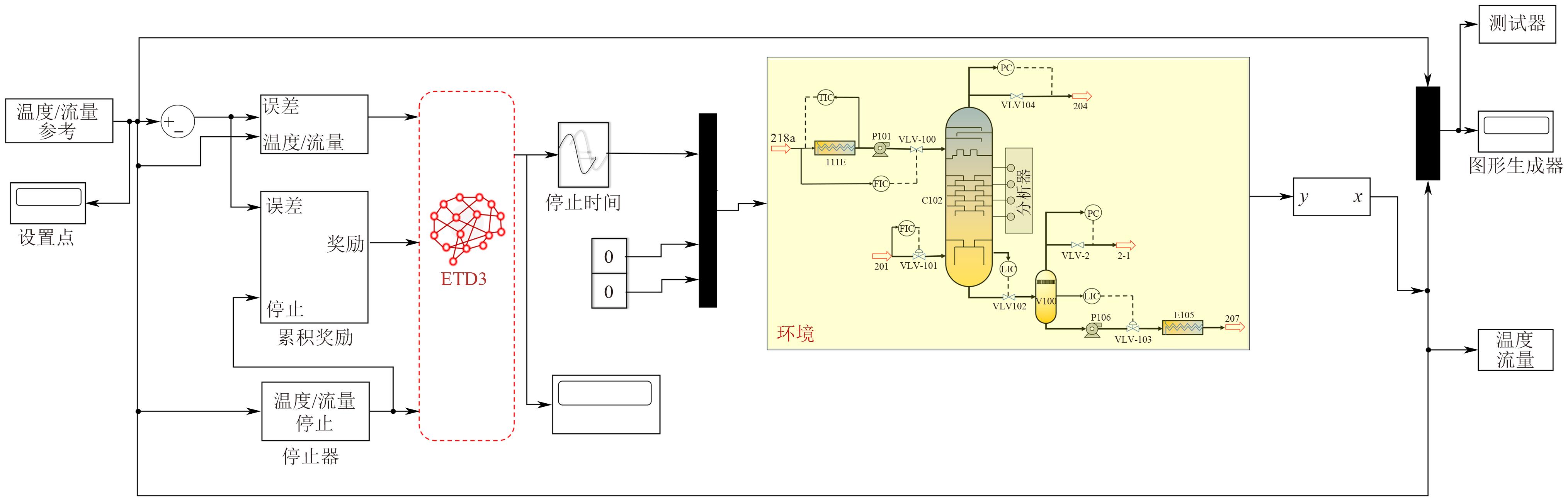
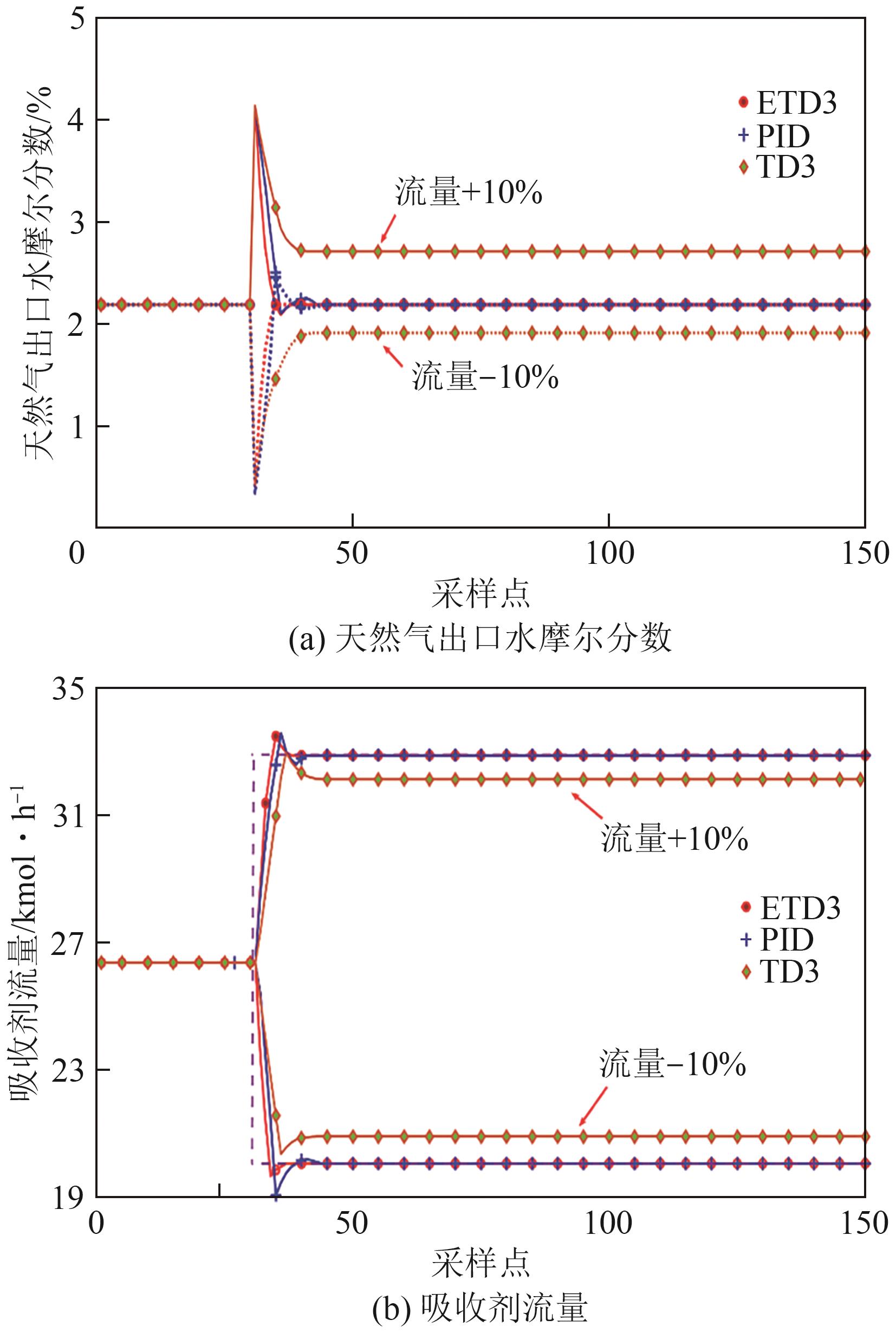
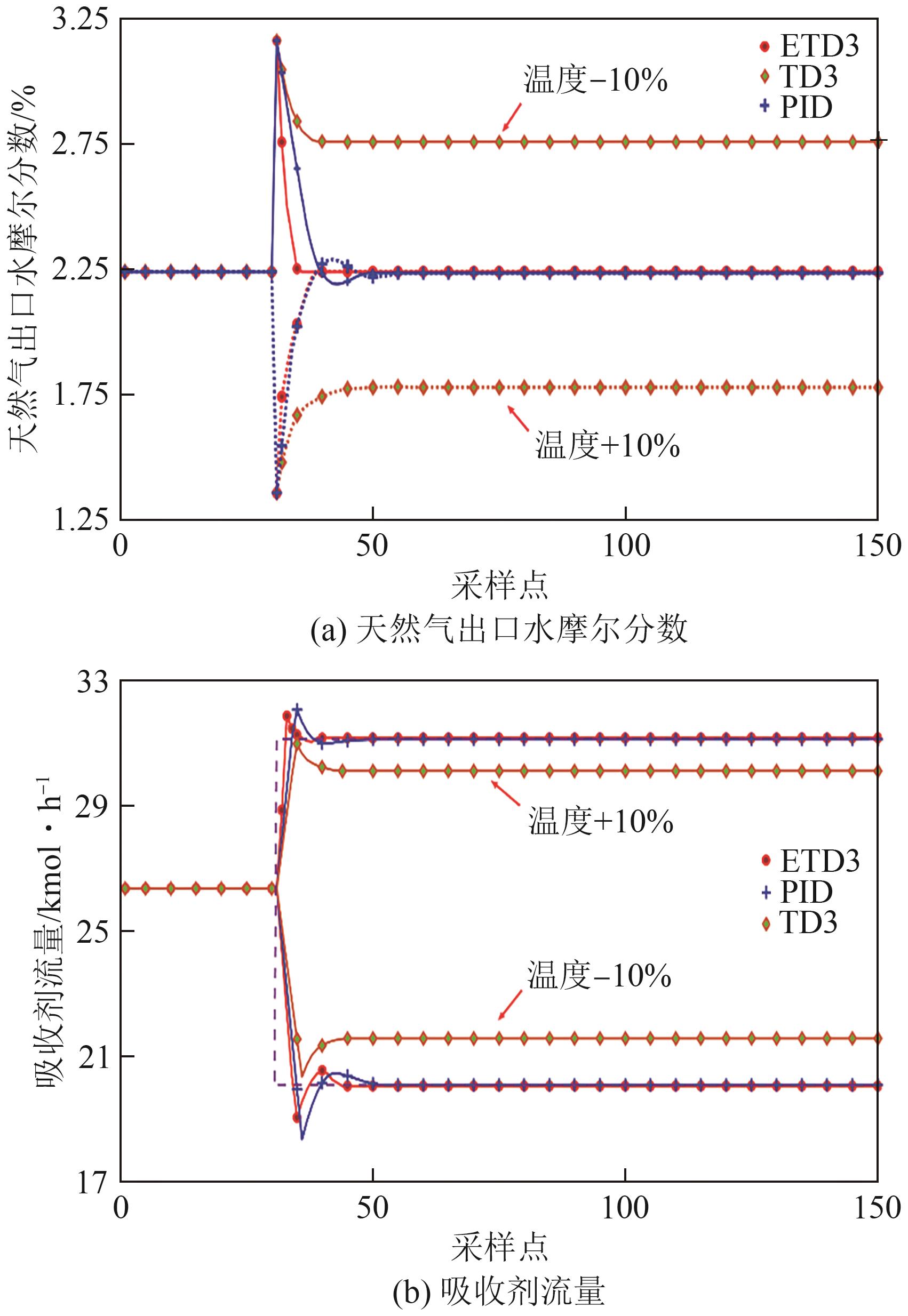
| [1] |
BORASE Rakesh P, MAGHADE D K, SONDKAR S Y, et al. A review of PID control, tuning methods and applications[J]. International Journal of Dynamics and Control, 2021, 9(2): 818-827.
|
| [2] |
MNIH Volodymyr, KAVUKCUOGLU Koray, SILVER David, et al. Playing atari with deep reinforcement learning[EB/OL]. (2013-12-19)[2024-08-07]. .
|
| [3] |
RODERICK Melrose, MACGLASHAN James, TELLEX Stefanie. Implementing the deep Q-network[EB/OL]. (2017-11-20)[2024-08-07]. .
|
| [4] |
Ki Uhn AHN, PARK Cheol Soo. Application of deep Q-networks for model-free optimal control balancing between different HVAC systems[J]. Science and Technology for the Built Environment, 2020, 26(1): 61-74.
|
| [5] |
VARGA Balázs, Balázs KULCSÁR, CHEHREGHANI Morteza Haghir. Deep Q-learning: A robust control approach[J]. International Journal of Robust and Nonlinear Control, 2023, 33(1): 526-544.
|
| [6] |
CHEN Zheyi, HU Jia, MIN Geyong, et al. Adaptive and efficient resource allocation in cloud datacenters using actor-critic deep reinforcement learning[J]. IEEE Transactions on Parallel and Distributed Systems, 2022, 33(8): 1911-1923.
|
| [7] |
ZHENG Yan, LI Xutong, XU Long. Balance control for the first-order inverted pendulum based on the advantage actor-critic algorithm[J]. International Journal of Control, Automation and Systems, 2020, 18(12): 3093-3100.
|
| [8] |
XIAO Qinge, YANG Zhile, ZHANG Yingfeng, et al. Adaptive optimal process control with actor-critic design for energy-efficient batch machining subject to time-varying tool wear[J]. Journal of Manufacturing Systems, 2023, 67: 80-96.
|
| [9] |
QIU Chengrun, HU Yang, CHEN Yan, et al. Deep deterministic policy gradient (DDPG)-based energy harvesting wireless communications[J]. IEEE Internet of Things Journal, 2019, 6(5): 8577-8588.
|
| [10] |
JESUS Junior C, BOTTEGA Jair A, CUADROS Marco A S L, et al. Deep deterministic policy gradient for navigation of mobile robots in simulated environments[C]//2019 19th International Conference on Advanced Robotics (ICAR). Belo Horizonte, Brazil: IEEE, 2019: 362-367.
|
| [11] |
JOSHI Tanuja, MAKKER Shikhar, KODAMANA Hariprasad, et al. Twin actor twin delayed deep deterministic policy gradient (TATD3) learning for batch process control[J]. Computers & Chemical Engineering, 2021, 155: 107527.
|
| [12] |
YUAN Xiaoming, WANG Yu, ZHANG Ruicong, et al. Reinforcement learning control of hydraulic servo system based on TD3 algorithm[J]. Machines, 2022, 10(12): 1244.
|
| [13] |
SHEHAB Mazen, ZAGHLOUL Ahmed, Ayman EL-BADAWY. Low-level control of a quadrotor using twin delayed deep deterministic policy gradient (TD3)[C]//2021 18th International Conference on Electrical Engineering, Computing Science and Automatic Control (CCE). Mexico: IEEE, 2021: 1-6.
|
 ), DONG Lichun(
), DONG Lichun(